
Things I Brushed Up On This Week
The HTTP Request Lifecycle
I have been interviewing for jobs recently, and as most devs know, the breadth and depth of questions you can expect to be asked during an interview is pretty much immeasurable. With that in mind, I have been probing recruiters on what I can expect to be asked during technical rounds. Maybe it is the mark of a weak dev, but I find it hard to maintain all the possible categories of questions I can expect straight in my head, let alone the questions themselves. I tend to forget things under pressure, like that | in bash is for processes/programs and > is generally for files. In service of wanting to retain the information better and force myself to write, I have decided to start posting walkthroughs of what I brush up on. I tend to require at least 3 sources to get a complete, correct, and well-written explanation of a topic. I would like to consolidate that for other people.
This week, I went over the HTTP request lifecycle. This is a pretty broad overview, and it is for a simple HTTP 1.1 request, not a persistent connection, but it could act as a good jumping-off point for HTTP/2 and persistent connection requests. I will not cover too much about the various HTTP methods because that could be a post on its own, and because they are close enough to many developers’ workflow that the reader could probably recite the basics already.
Step 1: Local Processing
Depending on how in depth you want to get, much can happen during this step depending on the application making the request. I am going to proceed on the understanding this request is being made by a browser, as opposed to cURL, an API client like Postman, or some other app.
Your browser extracts the "scheme"/protocol (we have established
that this will be HTTP), host (www.example.com),
and optional port number, resource path, and query strings that are specified in the form
<protocol>://<host><:optional port>/<path/to/resource><?query>. An example is|http|://|www.example.com||:5000||/mainpage||?query=param&query2=param2|

Now that the browser has the intended hostname for the request, it needs to resolve an IP address1. The browser will then look through its own cache of recently requested URLs, the operating system’s cache of recent queries, your router’s cache, and your DNS cache.
Step 2: Resolve an IP
Like the processing done locally, resolving an IP from a "DNS server"2 is a sequence that includes many steps, and includes failovers if the first request fails to return an address.
If the cache lookup fails (we will assume it does), your browser fires off a DNS request using UDP3. The DNS request contains the preconfigured IP for your DNS server and your return IP in its header. The hostname for which you are trying to resolve an IP is in the request’s "Question" section. UDP is a lightweight protocol, but the tradeoff is that it offers no guarantees in terms of delivery, and there is no acknowledgement other than a response being sent and received.

Your request will now have to travel many network devices to reach its target DNS server. Whenever the packet hits a piece of networking equipment, the device uses a routing table to determine which other device it is connected to that is most likely situated along the shortest path to the destination.4
Once your request arrives at your configured DNS server, the server looks for the address associated with the requested hostname. If it finds one, it sends a response. If, on the other hand, the DNS server you have targeted cannot locate the given hostname, it passes the request along to another DNS server it is configured to defer to. This happens recursively until the address is found, or an "authoritative" nameserver is hit. If an address for the given domain cannot be resolved, the server responds with a failure and your browser returns an error.
We will assume the request is successful though, given that all of this is still a precursor. If the response makes it back (remember, with UDP there’s no guarantee!), the requesting client now has a target IP. It will also have received a piece of information as part of the answer that will let it know how long the returned answer can be cached for. This means subsequent requests will get to take a shortcut from Step 1.2 to here.
Step 3: Establish a TCP Connection
Now that the client has an IP address, it can send an HTTP5 request, right? Almost, but first, since the request is sent over TCP6, which is a transport layer protocol like UDP, the client must open a TCP connection.
One of the key differences between TCP and UDP is that TCP ensures delivery and ordered data transmission. Much of this is done very simply, using what’s known as a sequence number for every byte sent. This allows the receiver to re-order received packets back into their original order, and allows the sender to retransmit any packet that does not get acknowledged by the receiver.
-
These guarantees and more can be found on Wikipedia, and are worth reading about, but what’s most relevant is that TCP connections are opened using what’s known as a three-way handshake. The server must already be "listening" on a port, performing a passive open, after which the client can initiate an active open, and the handshake works as follows:
- The client initiates the active open by sending a
SYN7 "control"8 packet to the server. The client sets the sequence number for the first packet to a random value purposely, in service of security. We’ll refer to this number asxfor now. - The server responds with a
SYN-ACK9 message, which contains an acknowledgement number for the original message that is alwaysx+1, and a new sequence number for the response itself, which is another random numbery. - In the third step, the client sends an
ACK10 message back to the server with a sequence number equal tox+1, which should match theSYN-ACKmessage’s acknowledgment number and ensure that our data is being delivered reliably. TheACKmessage’s acknowledgment number (since it is acknowledging theSYN-ACK) is set to one more than the received sequence number, ory+1.
- The client initiates the active open by sending a
We now have a completed three-way handshake and an established connection where both the client and server have received acknowledgment of the connection from the other party. The connection has also established a random, sequential sequence11 for each direction of communication (client->server, server->client), allowing for bidirectional, concurrent communication along the connection, which is also known as full duplex communication.
Step 4: Send an HTTP Request
Wow, that was a bunch of steps! But now that the client has an IP address and a TCP connection, it can finally send an HTTP request! Except…..no I’m kidding, we can send a request for real this time!
The request is made up of a "request line", request header, and a body. The "request line" is simply a line that indicates the HTTP method, the resource being requested, and the protocol version. The header of the request is made up of pairs in the form
name:value <CR><LF>. Two consecutive<CR><LF>pairs indicate the end of the header section. The only mandatory field in an HTTP request isHOST, which contains the domain and port that the request is being sent to (domain.com:8080), although in some cases the port can be omitted. Outside of the host field, common standard HTTP header fields includeOrigin,Accept,Accept-Encoding, and many more. The request can also include any non-standard header fields, and historically non-standard fields are indicated by prefixingX-to the field’s name. The body content of an HTTP request is completely optional, but often contains something like form data or JSON.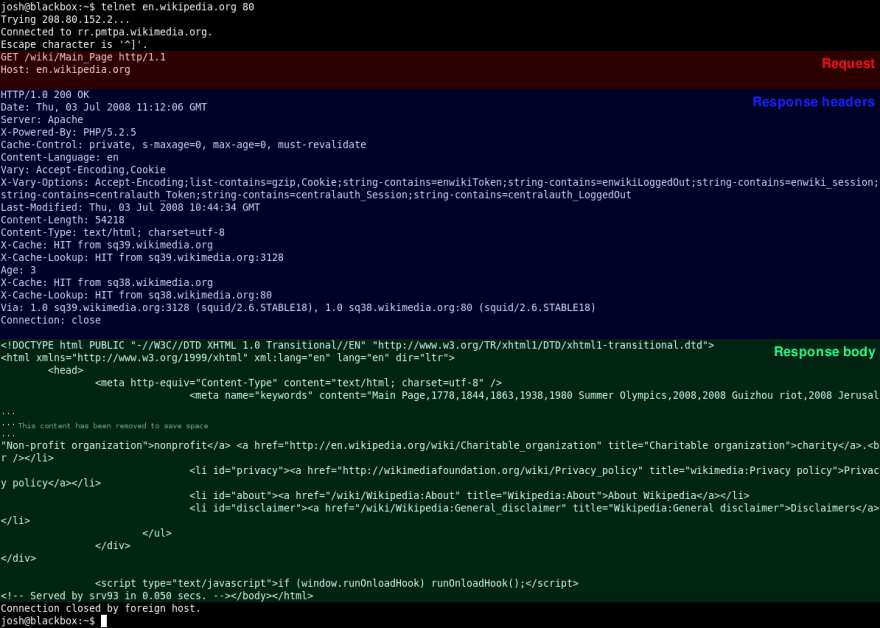
Once the HTTP request is sent, it follows a similar routing procedure as the one discussed earlier, with the difference being that using TCPs magic sequence number powers, the server can ensure it receives the whole request, in the correct order.
Once the server receives the request, processes it, and finds the resource being requested, it generates an HTTP response. An HTTP response has a similar structure to an HTTP request, containing a "status line", response header fields, and an optional body. The status line contains an HTTP status code indicating the success, failure, or error-state of the request along with a "reason message" that provides detail.
Once the response is generated, the server responds to the request. At the TCP layer, the client receives the first data packet, the first byte of which should contain the HTTP response header. More packets start coming in, and at the TCP layer they are re-ordered as needed. For every two packets that the client receives at the TCP layer, it sends an
ACKmessage to the server. This goes on until the response is (hopefully) fully loaded.
Step 5: Tearing Down and Cleaning Up
We’re almost there!
Once the response has been fully delivered, the client sends a
FINpacket at the TCP level, to which the server responds with anACK, and then generally sends aFINof its own, which the client responds to with its ownACKsignal. The client then waits for a brief timeout, during which it cannot accept new connections, to prevent delayed packets from previous connections arriving during subsequent activities on the port. This four way handshake12 signals the end of the TCP connection.At this point, your browser begins processing what it has received. If it is an image, data, or other media file that is being consumed by some application inside the browser, a variety of things can happen. If the data received is HTML, the browser will start parsing the HTML, and rendering the page you requested. As it parses, the browser may come across links to images or other media that are external to the HTML it has received, and will spin up new requests for that content, restarting this whole process (although usually skipping steps 1 & 2 thanks to caching). But, given that we were only interested in the lifecycle of an individual request: our (application’s) work is done, congratulations!
All of the above is, again, only a description of a simple HTTP transaction, not a persistent transaction, which would maintain the same connection for multiple requests, but that model doesn’t differ heavily outside of behavior that occurs once the TCP connection is open and the first control packets are exchanged. It also doesn’t cover parallel HTTP transactions, which spin up additional connections for subsequent requests once the first request’s connection is established, but again, the lifecycle doesn’t change much. Primarily, these other approaches help mitigate something you probably noticed as you were reading: the handshaking spin-up and tear-down procedures of a single TCP connection can be very time consuming, and developers have the ability to avoid re-performing them or performing them consecutively.
Well, that is it, that is the multi-layer lifecycle of a single HTTP request! Thanks for reading, please let me know what you think, and if you feel that any corrections are needed please reach out!
-
For the layman, an Internet Protocol Address is a numeric identifier for a computer, server, or other resource connected to a TCP/IP network. If you have never seen those terms I would suggest reading a primer on how the internet works before proceeding, because this post is a breakdown of a portion of that. ↩
-
This is a server that serves a collection of hostnames and their correlated IPs. ↩
-
If the request or response is greater than the size of a single packet, the browser uses a TCP request instead. This will happen with IPv6 and DNSSEC responses. UDP is a lightweight protocol that optimizes for speed, with the tradeoff being that it offers no guarantees in terms of delivery or order. It is well-suited for use-cases where error-checking can be outside the network interface and packet-loss is preferable to delayed delivery. There is no handshake, so there is no acknowledgement other than a response being sent and received. ↩
-
Shoutout to E.O. Stinson on Quora for being the only source to mention this (that I could find). Much of his answer on Quora informed my notes. ↩
-
HTTP (Hyper*text **Transfer **Protocol) is an “application-layer protocol that generally assumes use of TCP as its “transport-layer protocol (Although there are implementations that can use protocols like UDP). We won’t go into what this means too much, but it’s good to understand that everything happening when we’re discussing HTTP is usually happening a layer *above the one we were previously discussing, which means we can take more things for granted. ↩
-
TCP (Transmission Control Protocol) ↩
-
which stands for “Synchronize” ↩
-
This is a packet that doesn’t contain request/response-specific information, and is simply used to manage the transaction ↩
-
which stands for “Synchronize Acknowledgment” ↩
-
I guess they got lazy with the names :D ↩
-
also called a connection parameter ↩
-
Although the implementation varies and can be condensed into 3 steps ↩


















