This is a Plain English Papers summary of a research paper called SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
• This paper introduces SaySelf, a system that teaches large language models (LLMs) to express confidence in their own responses by generating self-reflective rationales.
• The key idea is to train LLMs to not only generate outputs, but also to reason about and justify their own responses, which can help users better understand the model's level of confidence and reasoning.
• The authors demonstrate that this approach can improve the calibration of LLM confidence, leading to more reliable and transparent language models.
Plain English Explanation
The paper describes a new approach called SaySelf that aims to make large language models (LLMs) more transparent and reliable. LLMs are AI systems that can generate human-like text, but they don't always express how confident they are in their responses.
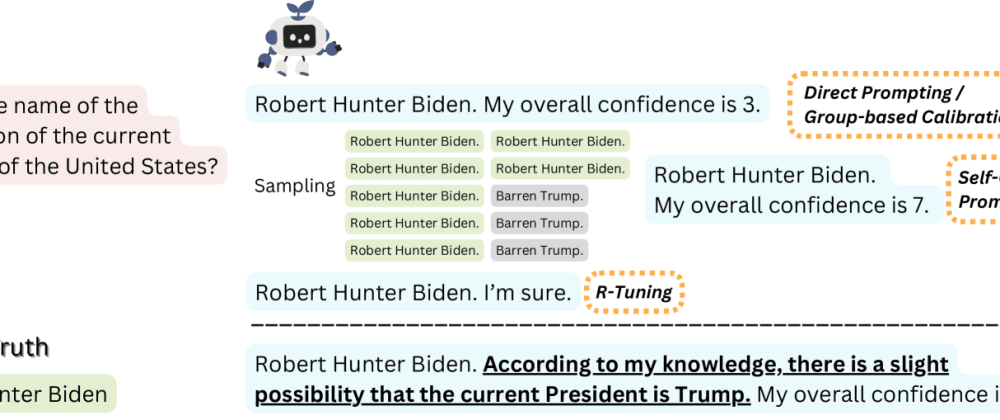
The core idea of SaySelf is to train LLMs to not only generate outputs, but also to explain their own reasoning and confidence levels. So, in addition to giving an answer, the model would also provide a self-reflective rationale that justifies its response.
For example, if asked "What is the capital of France?", a SaySelf-enabled model might respond: "I'm very confident that the capital of France is Paris, because France is a country in Western Europe and Paris is widely known as its capital city."
By having the model explain its thought process, users can better understand how reliable the model's response is. This can help improve trust in the model and make it more transparent.
The authors show through experiments that this approach can lead to LLMs that are better calibrated - meaning their expressed confidence levels better match their actual accuracy. This makes the models more reliable and trustworthy for real-world applications.
Technical Explanation
The key innovation of this paper is the introduction of the SaySelf framework, which trains large language models (LLMs) to not only generate outputs, but also to provide self-reflective rationales that explain their reasoning and confidence levels.
To implement this, the authors utilize a multi-task learning approach. The model is trained on a primary task, such as question answering or text generation, as well as an auxiliary task that requires the model to generate a self-reflective rationale alongside its primary output.
The rationale is produced by a separate output head in the model's architecture, which is trained to summarize the model's reasoning process and estimate its own confidence. This allows the model to express its level of certainty about a given response.
The authors evaluate SaySelf on a range of language understanding and generation tasks, and show that it leads to significant improvements in confidence calibration - meaning the model's expressed confidence aligns better with its actual accuracy. This makes the model's outputs more reliable and transparent for users.
Some key technical insights from the paper include:
- The importance of multi-task learning to imbue LLMs with self-reflection capabilities
- Novel architectures that decouple response generation and self-reflection
- Effective training strategies to encourage models to develop accurate self-awareness
Critical Analysis
The SaySelf approach represents an important step towards more transparent and reliable large language models. By teaching LLMs to reason about and justify their own outputs, the authors address a key limitation of current models, which can sometimes produce confident-sounding but inaccurate responses.
That said, the paper does not delve deeply into potential limitations or failure modes of the SaySelf approach. For example, it's unclear how well the self-reflective rationales would generalize to out-of-distribution inputs, or how robust the confidence calibration would be to adversarial attacks.
Additionally, the added complexity of the SaySelf architecture and training process could make the models more computationally expensive or slower to deploy. The authors do not provide a thorough analysis of the tradeoffs in terms of efficiency and scalability.
Further research is also needed to understand how users interpret and respond to the self-reflective rationales in real-world applications. While the improved confidence calibration is promising, more user studies are required to validate the impact on trust and transparency.
Overall, the SaySelf framework represents an important advance in the field of trustworthy AI, but there are still open challenges and avenues for further exploration. Rigorous evaluation of the approach's limitations and real-world implications will be crucial as this line of research progresses.
Conclusion
This paper introduces SaySelf, a novel framework for training large language models to not only generate outputs, but also to provide self-reflective rationales that explain their reasoning and confidence levels. By imbuing LLMs with this self-awareness, the authors demonstrate significant improvements in confidence calibration, making the models' responses more reliable and transparent.
The SaySelf approach represents an important step towards developing AI systems that can better communicate their capabilities and limitations to users. As language models become increasingly pervasive in real-world applications, techniques like this will be crucial for building trust and ensuring these powerful tools are used responsibly and effectively.
While the paper does not address all potential limitations of the approach, it lays the groundwork for further research and development in the area of trustworthy AI. Continued progress in this direction could lead to a new generation of language models that are not only highly capable, but also self-aware and able to explain their inner workings.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.


















